
Microservices (μServices) are a fascinating evolution of the Distributed Object Computing (DOC) paradigm. Initial design of DOC attempted to solve the problem of simplifying developing complex distributed applications by applying object-oriented design principles to disparate components operating across networked infrastructure. In this model, DOC “hid” the complexity of making this work from the developer regardless of the deployment architecture through the use of complex frameworks, such as Common Object Request Broker Architecture (CORBA) and Distributed Component Object Model (DCOM).
Eventually, these approaches waned in popularity as the distribution frameworks were clumsy and the separation of responsibilities between developer and operations did not meet with the promised goals. That is, developers still needed to understand too much about how the entire application behaved in a distributed mode to troubleshoot application problems and the implementation was too developer-centric to allow operations to be able to fulfill this role.
One aspect of this early architecture that did succeed, however, was the concept of the Remote Procedure Call (RPC). The RPC represented a way to call functionality inside of another applications across a network using the programming language function call constructs such as passing parameters and receiving a result. With the emergence of declarative syntaxes, such as XML, and then JSON, marshalling—the packaging of the data to and from the RPC—became simpler and the need for specialized brokers were replaced with generic transports, such as HTTP and asynchronous messaging. This gave rise to the era of Web Services and Service Oriented Architecture (SOA).
To make a long story short, Web Services were extremely popular, SOA, required too much investment in software infrastructure to be realized on a massive scale. Web Services was eventually rebranded Application Programming Interface (API)—there is really no difference architecturally between a Web Service and an API—and JSON became the primary marshalling scheme for Web-based APIs.
Apologies for the long-winded history lesson, but it is important to understand μServices in context. As you can see from this history the more we moved away from the principles of object-oriented toward a more straightforward client/server paradigm there was a rise in adoption. The primary reason for this is that architecture takes time, satisfies needs of longer-term goals, and requires skilled individuals that can often be expensive. With the growing need for immediacy driven by the expanding digital universe, these are characteristics that many business leaders believed were luxuries where speed was essential.
Needless to say, there was an immediate benefit of rapid growth of new business capabilities and insight into petabytes of data that was previously untouchable. Version 1.0 was a smashing success. Then came the need for 2.0. Uh-oh! In the race to get something fast, what was ignored was sustainability of the software. Inherent technical debt fast became the inhibitor to deriving 2.0 enhancements at the same speed as 1.0 was developed. For example, instead of envisioning that three applications all implemented similar logic and developing that once as a configurable component, it was developed three times each specific to a single application.
Having realized the value of architecture and object-oriented design that was dropped in favor of speed, the vacuum created was for a way to use the speedy implementation mechanics while still being able to take advantage of object-oriented design paradigm. The answer is μServices.
While Martin Fowler and others have done a great job explaining the “what” and “how” of μServices, for me the big realization was in the “why” (described herein). Without the “why” it’s too easy to get entangled in the differentiation between this and the aforementioned Web Services. For me, the “why” provided ample guidelines for describing the difference between a μServices, an API and a SOA service.
For simplicity I’ll review the tenets of OO here and describe their applicability to μServices:
- Information hiding – the internal representation of data is not exposed externally, only through behaviors on the object
- Polymorphic – a consumer can treat a subtype of an object identically to the parent. In this particular case, μServices that implements a particular interface can be consumed in the identical fashion
- Inheritance – the ability for one object to inherit from another and override one or more behaviors. In the case of μServices, we can create a new service that delegates some or all behavior to another service.
The interesting thing about these tenets as a basis for μServices, and subsequently the basis for the title of this article, is that answering the mail on this does not necessitate complete redevelopment. Indeed, in many cases, existing functionality can be refactored from the 1.0 software and packaged up using container technology delivering the exact same benefit as having developed the 2.0 version from scratch as a μService.
Let’s revisit our earlier dilemma that similar logic was developed three different times into three different applications. For purposes of this blog, let’s assume that is a tax calculation and was written once each for US, Canada and Europe. Each of these has a table implemented in a database. It would not take much work to take these different implementations, put them into a single μService with a single REST interface using a GET operation with the region and providing the necessary inputs on the query string. That new μService could then be packaged up inside a Docker container with its own Nginx (Web Server) and MySQL database with required tax tables for each region. In fact this entire process could probably be accomplished, tested and deployed in the span of a week. Now, we can create four new applications that all leverage the same tax calculation logic without writing it four more times.
This works great as long as the tax tables don’t change or we don’t want to add a new region. In that case, additional development would be required and the container would need to be re-created, tested and re-deployed.
Alternatively, we could develop a reusable tax service and deploy this new μService in a Platform-as-a-Service (PaaS). Assumedly, we could extend this service with new regions and changes to tax tables without impacting any other region, having to regression test the entire tax service, or take the μService out of service during the redeployment period. Moreover, the new region would be available simply by modifying the routing rules for the REST URL to accept the new region.
The diagram below illustrates these two different options. The .WAR file represents the deployable tax calculator. As you can see one or more containers would need to be either patched or re-created to deploy new functionality in the Deployment Architecture model, whereas we could continue to deploy multiple .WAR files in the PaaS Architecture, which would handle routing off the same URL-based interface giving appearance of being a single application.
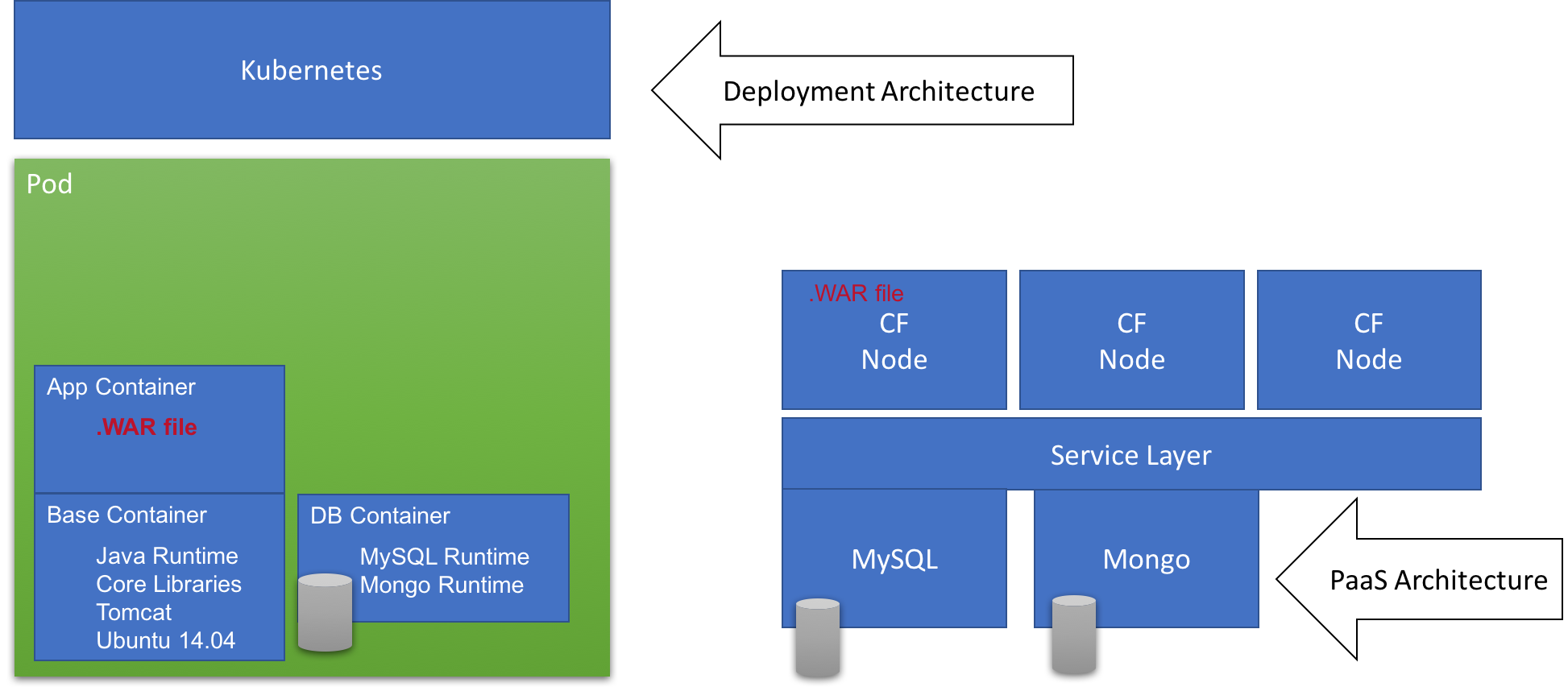
Thus, the two faces of μServices are those create through deployment and those created through design and development. As a lifelong software architect, I recognize the pragmatism in getting to market faster using the deployment architecture, but highly-recommend redesign and development for greater sustainability and longevity.
If you found this article useful, please leave a comment.
JP, how are you? No doubt this is a brilliant reading. Great article thanks and keep it up! Have a good day!
Thank you